Open-Source AI Platform or End-to-End Deployment
Discover a unified, open-source platform that tackles every phase of AI deployment —from data ingestion to real-time inference—built with today’s enterprise needs in mind.
Key Takeaways
- OpenRails unifies data ingestion, AI fine-tuning, and enterprise features under one open-source umbrella.
- It supports rapid deployment of chatbots, search tools, and customized AI solutions.
- The commercial open-source model provides a free core plus optional paid modules for advanced functionality.
- Perfect for organizations that want full control over AI workflows without building everything from scratch.
Introduction
As AI technologies mature, businesses often find themselves piecing together disparate tools—data ingestion pipelines, vector databases, model orchestration layers, front-end interfaces, and more—to create a complete, production-ready system. OpenRails offers a more unified approach. This open-source platform covers every step of AI deployment, from ingesting large datasets to fine-tuning models for domain specificity and serving real-time inferences. Below, we’ll explore why OpenRails was created, what it offers, and how its commercial open-source model supports businesses of all sizes.
Why OpenRails?
In a modern AI solution, multiple specialized components must work harmoniously:
Unified Platform
OpenRails simplifies the AI stack by providing an end-to-end framework. Rather than juggling various open-source libraries for web scraping, data storage, and inference endpoints, you can rely on an integrated ecosystem. This minimizes version conflicts, duplicated effort, and the overhead of piecemeal solutions.
End-to-End Lifecycle
Whether you’re ingesting thousands of policy documents or building a chatbot to answer real-time queries, OpenRails streamlines each step. For instance, data ingestion can be automatically normalized and stored in a vector database, and then leveraged by its retrieval-augmented generation (RAG) layer for more accurate AI responses.
Enterprise Customizability
Because it’s open source, you can adapt modules for your domain, self-host in compliance-heavy environments, and avoid vendor lock-in. This blend of flexibility and transparency appeals to businesses that need agility and control over their AI processes. 
Data Ingestion & Indexing
OpenRails accelerates your data pipeline with a suite of pre-built connectors and automated workflows:
- Out-of-the-Box Connectors: Scrape websites, parse PDFs, CSVs, JSON feeds, or pull from databases—all with minimal configuration.
- Batch & Streaming: Schedule daily batch ingests or process real-time event streams via Kafka or AWS Kinesis for up-to-the-minute freshness.
- Schema & Annotation: Auto-detect field types, normalize date formats, and apply custom labeling logic to surface metadata critical for downstream tasks.
- Vector Indexing: Instantly index embeddings into FAISS, Pinecone, or Elasticsearch KNN to enable sub-second semantic similarity searches.
Whether you’re building a recommendation engine or a Q&A bot, this foundation ensures your pipeline scales from thousands to millions of documents without re-inventing core ingestion logic. 
Fine-Tuning & Retrieval-Augmented Generation
Move beyond generic LLMs by tailoring models to your domain and grounding them in your own data:
- Domain-Specific Fine-Tuning: Ingest your internal manuals, support logs, or product catalogs to teach the model your brand’s acronyms, tone, and specialized vocabulary.
- Hybrid Retrieval Pipelines: At query time, OpenRails fetches the top-K relevant documents from the vector store, then injects that context into the prompt to the LLM.
- Configurable Prompts: Control instruction templates, temperature, and max tokens per use case—whether you need concise answers or exploratory brainstorming.
- Caching & Batching: Reuse prior retrieval results for popular queries and batch multiple requests to minimize latency and API costs.
The result is a retrieval-augmented generation pipeline that delivers highly accurate, context-aware responses—ideal for knowledge bases, virtual assistants, and decision support tools. 
Modular UI Components
OpenRails gives you a library of production-ready front-end modules to launch faster:
- Chatbot Widget: A floating chat overlay with rich message formatting, file uploads, and contextual follow-ups out of the box.
- Search Bar & Results: Instant typeahead, faceted filters, and paginated results pages—easily skinnable to match your brand.
- Dashboard Panels: Pre-built React or Vue components for usage metrics, top queries, and sentiment trend charts using recharts.
- Custom Hooks & APIs: Fetch live suggestions, record user feedback, or extend behavior with your own React hooks or JavaScript callbacks.
All components are responsive, ADA-compliant, and theme-aware—so you can drop them into your existing portal or corporate site without a major front-end rewrite. 
Monitoring & Logging
Maintain full visibility into your AI stack’s health and performance with built-in observability:
- Real-Time Dashboards: Track query volumes, average latency, error rates, and model confidence scores in Grafana or Kibana out of the box.
- Structured Logs: Each request/response pair is logged with timestamp, user ID, prompt text, retrieved documents, and output tokens for audit and debugging.
- Alerting & SLA: Define thresholds for slow responses or spike in 5xx errors—triggering Slack or PagerDuty alerts to your DevOps team.
- Usage Analytics: Identify top search terms, common fallback questions, and low-performing intents to guide retraining priorities.
With this end-to-end observability, you can proactively tune your models, troubleshoot bottlenecks, and demonstrate compliance to stakeholders and auditors alike.
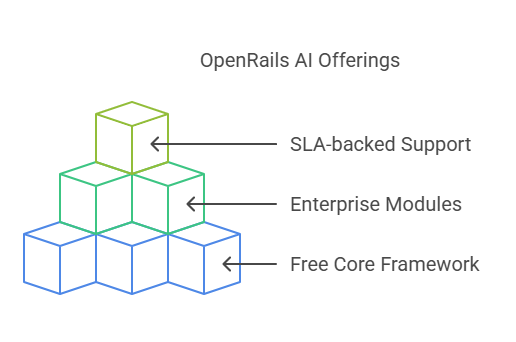
Commercial Open Source Approach
OpenRails follows a dual-licensing strategy that balances open-source accessibility with enterprise-grade capabilities. Whether you’re a lean startup or a large regulated organization, you can pick and choose exactly the features and support you need, while contributing back to a vibrant community.
Free Core
At its heart, OpenRails provides a fully open-source core under a permissive license (Apache 2.0 or MIT). This includes:
- Data Connectors: Web scraping, PDF/CSV/JSON ingestion, and database pulls out-of-the-box.
- Vector Indexing & RAG: Seamless embedding storage and retrieval-augmented generation pipelines.
- Modular UI Toolkit: Basic chatbot and search components ready to embed in any web portal.
- Core Observability: Basic logging and metrics endpoints to plug into Prometheus or Grafana.
This free layer removes barriers to experimentation: spin up a proof-of-concept in hours, run pilots without license costs, and validate ROI before investing in advanced features. 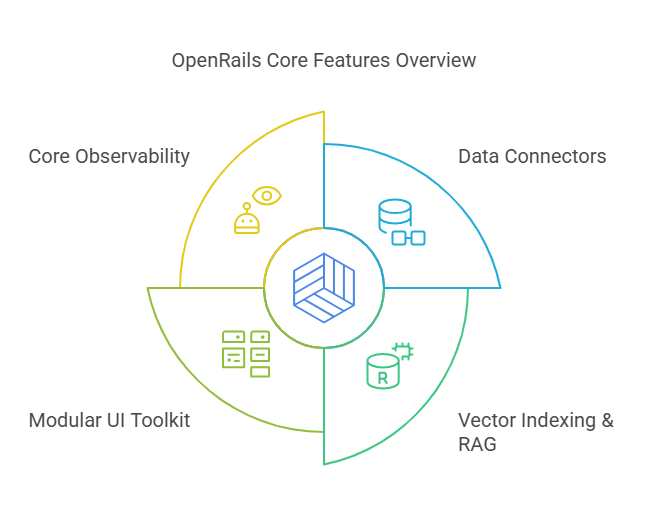
Paid Modules & SLA
Enterprises with mission-critical requirements can extend OpenRails via premium modules and service-level agreements:
- Advanced Analytics: Heatmaps of query flow, drift detectors, and automated retraining triggers.
- Specialized Connectors: Out-of-the-box integrations for Salesforce, Workday, ServiceNow, and niche CRMs.
- High-Availability SLA: Guaranteed 99.9% uptime, disaster recovery plans, and priority incident response.
- Professional Services: Onboarding workshops, custom prompt engineering, and performance tuning engagements.
By separating these into paid tiers, OpenRails remains financially sustainable, funding continued development of the free core while offering enterprises the assurances and customizations they require. 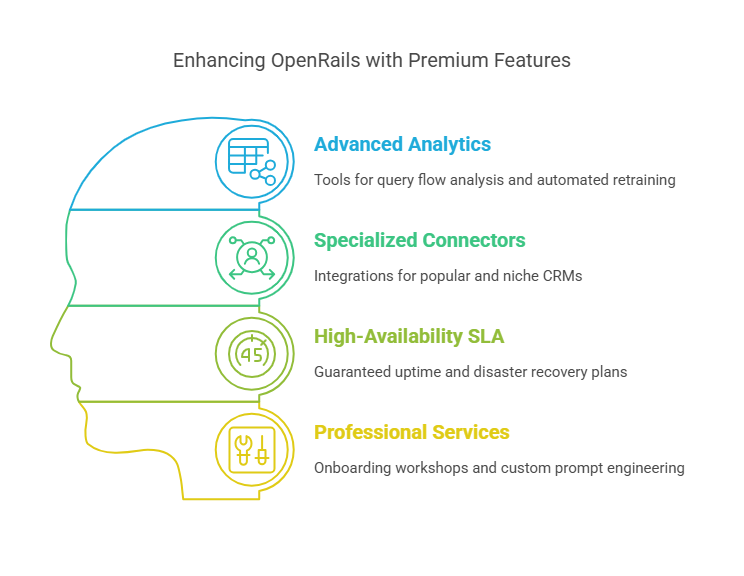
Community & Ecosystem
A thriving ecosystem of developers, data scientists, and integrators powers OpenRails forward:
- Plugin Marketplace: Community-contributed connectors for niche data sources and custom UI themes.
- Open Governance: Public GitHub repo, transparent roadmap, and RFC process for feature proposals.
- Knowledge Sharing: Weekly meetups, Slack channels, and quarterly hackathons to showcase real-world implementations.
- Educational Resources: Tutorials, sample apps, and expert-led webinars covering advanced RAG patterns and MLOps best practices.
This open ecosystem accelerates development cycles—innovations by one organization instantly benefit all, and shared best practices help new users ramp up in days instead of weeks.
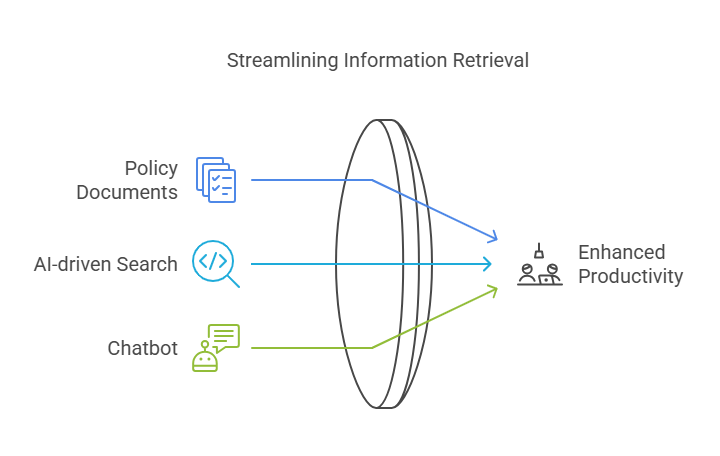
Sample Use Case: Internal Knowledge Base
Consider a mid-sized consulting firm with thousands of scattered policy documents, case studies, and process guidelines across network drives and SharePoint. Building a centralized, AI-powered internal knowledge base unlocks these assets for every employee—dramatically reducing search time and improving consistency.
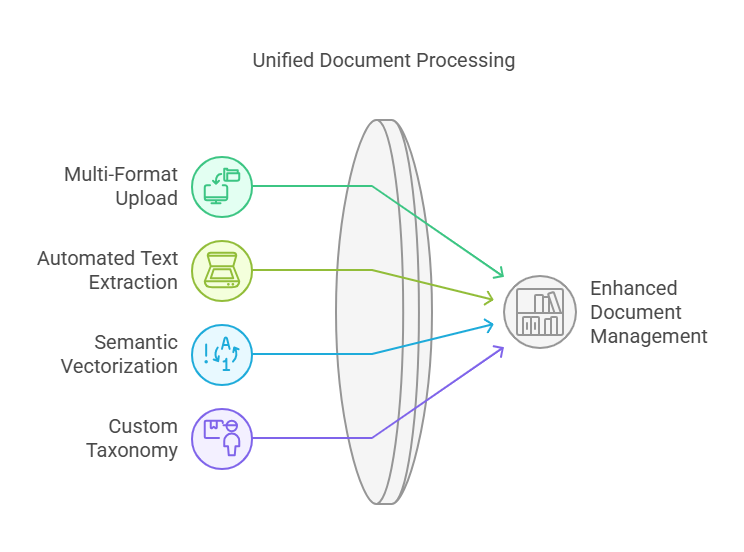
Ingest & Index
- Multi-Format Upload: Drag-and-drop PDFs, Word docs, spreadsheets, or PPT decks.
- Automated Text Extraction: OCR for scanned pages, metadata parsing for author, date, and tags.
- Semantic Vectorization: Convert each page or section into embeddings and store in a FAISS or Pinecone index.
- Custom Taxonomy: Map documents to organizational domains—HR, Finance, Delivery—using lightweight classification models.
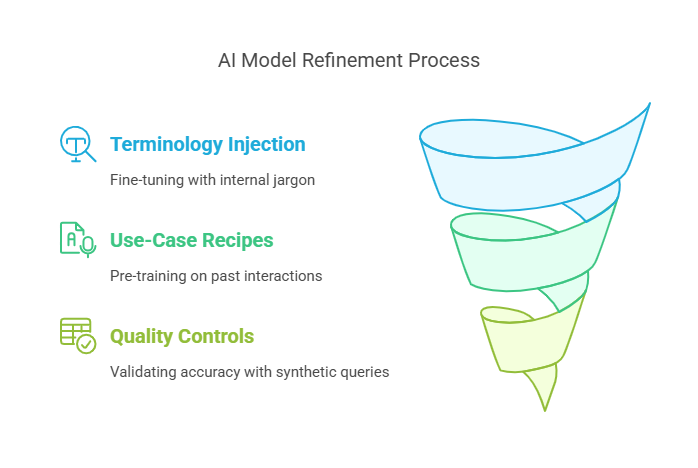
Domain Fine-Tuning
- Terminology Injection: Fine-tune the LLM on internal glossaries, slide decks, and email threads so it understands “client discovery frameworks,” “engagement scoring,” and other proprietary jargon.
- Use-Case Recipes: Pre-train on past Q&A transcripts to ensure the AI suggests correct next-steps or escalation paths.
- Quality Controls: Run synthetic queries against known answers to validate model accuracy before rollout.
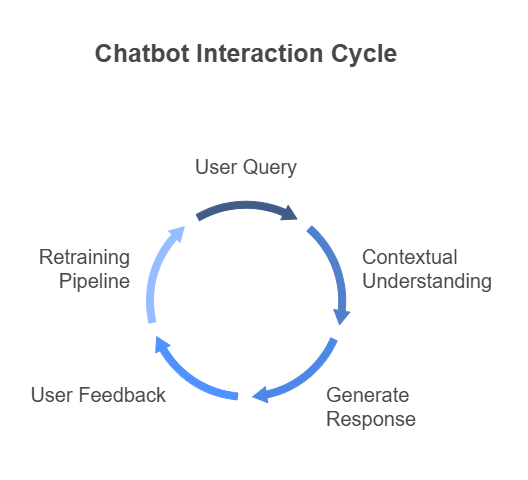
Employee Chatbot
Embed a branded chatbot widget on the firm’s intranet or Teams channel:
- Natural Language Queries: “How do I request a travel advance?” “What’s our policy on data retention?”
- Contextual Follow-Ups: The bot remembers user context—if you ask about “that policy,” it links back to the previous topic.
- Document Linking: Generate answers with clickable references back to the original PDF or slide deck.
- Feedback Loop: Users can upvote or flag incorrect responses, feeding corrections back into the retraining pipeline.
Continuous Updates
New materials automatically flow into the system:
- Watch Directories: Monitor network folders or SharePoint libraries and ingest new files hourly.
- Delta Indexing: Only process changed pages to keep indexing costs low and ensure sub-hour freshness.
- Retraining Triggers: When usage analytics detect high-value new topics, schedule an incremental fine-tuning job.
Conclusion
OpenRails was created to meet the growing demand for a unified, open AI platform that bypasses the pitfalls of fragmented libraries and proprietary vendor lock-in. By marrying a free core (covering ingestion, indexing, and basic RAG) with optional paid modules (e.g., advanced analytics or specialized connectors), OpenRails caters to both emerging startups and large enterprises. Whether you’re launching an internal knowledge base, building a chatbot, or deploying a domain-specific search tool, OpenRails provides a powerful, customizable launchpad tailored to modern business needs.
Ready to Explore OpenRails?
Interested in seeing how OpenRails can streamline your AI initiatives? Request a demo today to discover how it fits within your existing ecosystem.