Build the Optimal AI Tech Stack for Secure, Scalable Growth
Key Takeaways
- Choosing a robust framework aligns your AI initiative with long‑term goals and team expertise.
- Your stack must support scalability, performance, and secure integrations at both infrastructure and application levels.
- Evaluate local libraries (PyTorch, TensorFlow) vs. managed platforms (Vertex AI, SageMaker) based on control vs. convenience.
- A modular architecture ensures you can swap AI components or scale with minimal disruption.
- Emphasize best practices in data handling, testing, security, and continuous deployment to maintain reliability.
Introduction
Deploying AI in a business environment is more than selecting a cutting‑edge algorithm. You need a stable, scalable framework that ties together data pipelines, orchestration layers, security policies, monitoring dashboards, and more. Early framework decisions ripple through cost, performance, and maintainability for years. This guide walks you through how to select an AI development framework and extend it sustainably, ensuring your organization can iterate rapidly while minimizing technical debt.
The Importance of a Solid Framework
Laying the right foundation for your AI project ensures long-term stability, rapid development, and robust security. A well-chosen framework accelerates every phase—from prototyping to production—so you can focus on solving business problems, not reinventing infrastructure.
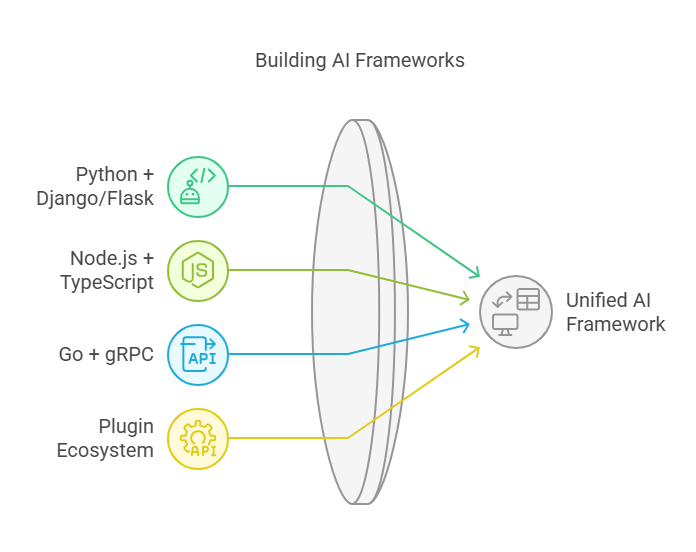
Future-Friendly Design
Just as Rails and Django revolutionized web development a decade ago, today’s AI initiatives demand frameworks with vibrant ecosystems:
- Python + Django/Flask: Leverage Python’s rich ML libraries (NumPy, pandas, scikit-learn) alongside Django’s ORM, routing, and authentication for end-to-end solutions.
- Node.js + TypeScript: Use TypeScript for strong typing and popular bindings like TensorFlow.js or ONNX Runtime to run models directly in JS backends or serverless functions.
- Go + gRPC: For performance-critical inference services, Go’s concurrency model and gRPC stubs deliver sub-millisecond latency at scale.
- Plugin & Extension Ecosystem: Mature frameworks boast hundreds of community plugins—everything from GraphQL integrations to real-time WebSocket modules—so you’re never stuck building boilerplate.
Choosing a framework with an active community and regular updates protects you from obsolescence and security risks, giving you a runway for years of iterative improvements.
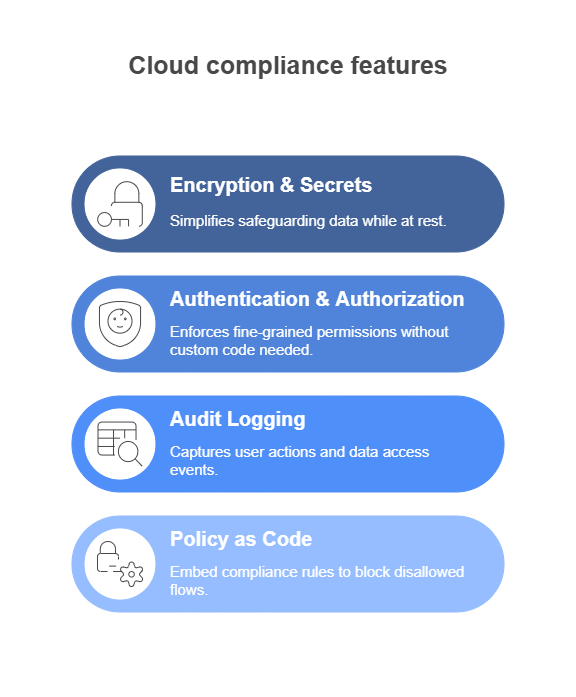
Security & Compliance
When your AI solution handles sensitive or regulated data, “secure by design” is mandatory—not optional:
- Encryption & Secrets Management: Frameworks with first-class support for TLS, AES encryption, and secret stores (Vault, AWS KMS) simplify safeguarding data at rest and in transit.
- Authentication & Authorization: Built-in OAuth2, JWT, and role-based access control modules enforce fine-grained permissions without custom code.
- Audit Logging: Choose stacks that capture user actions, API calls, and data access events in structured logs, easing compliance with SOC-2, HIPAA, GDPR, or CCPA.
- Policy as Code: Some frameworks support embedding compliance rules directly (e.g., Open Policy Agent), letting you automatically block disallowed data flows.
By picking a framework with native security features, you reduce your attack surface, accelerate audits, and maintain user trust from day one.
Integration Ecosystem
AI rarely exists in a silo. Your framework should make it painless to connect with the rest of your stack:
- Databases & Caching: Out-of-the-box ORM support for SQL, NoSQL, and Redis/Memcached reduces glue code and ensures consistent data access.
- Message Queues: Native adapters for Kafka, RabbitMQ, or AWS SQS let you build event-driven pipelines and microservices architectures.
- Third-Party APIs: SDKs or REST clients for popular services—payment gateways, CRMs, analytics platforms—accelerate integration and minimize boilerplate.
- Monitoring & Telemetry: Framework hooks for Prometheus, OpenTelemetry, or cloud-native tracing capture performance metrics and distributed traces.
A rich integration ecosystem ensures your team spends less time wiring services together and more time on core AI features—accelerating delivery and reducing maintenance overhead.
Integrating AI Tools
Selecting the right combination of libraries and platforms is crucial for balancing control, cost, and time-to-market. Below are three common integration strategies—each suited to different team skill sets and project needs.
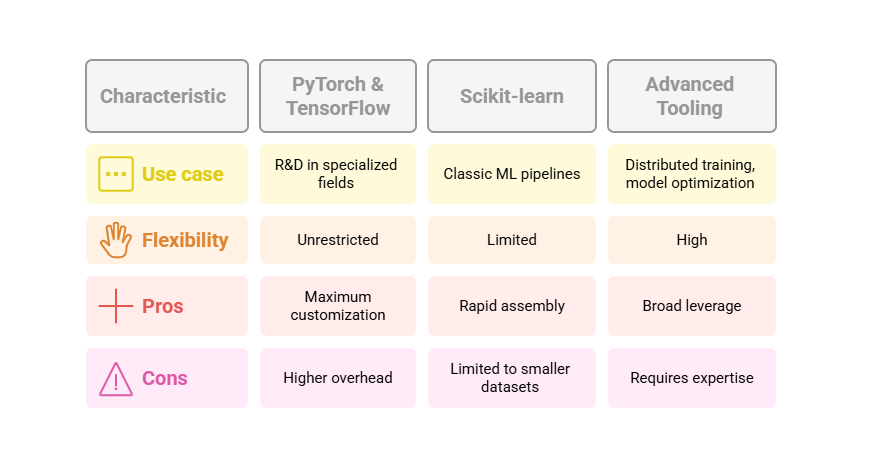
Local Libraries for Full Control
Ideal when your team includes experienced data scientists and MLOps engineers, local libraries give you unrestricted flexibility:
- PyTorch & TensorFlow: Build custom training loops, prototype novel architectures, and optimize kernels for GPU or TPU clusters. Perfect for R&D in computer vision, recommendation algorithms, or generative models.
- Scikit-learn: Rapidly assemble classic ML pipelines—feature engineering, cross-validation, grid search—without deep neural networks. Great for churn models, credit scoring, or text classification tasks under 1 million records.
- Advanced Tooling: Leverage tools like Ray for distributed training, ONNX for model interoperability, and Nvidia TensorRT for inference acceleration.
Pros: Maximum customization, no vendor lock-in. Cons: Higher operational overhead for cluster management, versioning, and scaling.
Managed Cloud Platforms for Speed
When rapid deployment and ease of maintenance trump full control, managed services streamline the AI lifecycle:
- Google Vertex AI: End-to-end support from data labeling to feature stores and model monitoring. Native integration with BigQuery and Dataflow simplifies ETL and analytics at petabyte scale.
- AWS SageMaker: One-click training jobs, built-in hyperparameter tuning, distributed training support, and automatic model deployment to auto-scaling endpoints—minimizing DevOps overhead.
- Azure ML: Collaborative workspaces, ML pipelines, and managed compute clusters with enterprise-grade security and Azure Active Directory integration.
Hybrid Approaches
Many organizations adopt a hybrid model: research and prototyping happen on-premises for data privacy, then production models deploy to the cloud for elasticity and global reach.
- Local-to-Cloud CI/CD: Train and validate models in a secure on-prem environment, then push Dockerized inference services to AWS, GCP, or Azure for public consumption.
- Edge & Cloud Mix: Deploy lightweight, quantized models at the network edge (IoT devices or on-site servers) for low-latency needs, with fallback to cloud for heavyweight computations.
- Cost Optimization: Use spot or preemptible instances for non-critical training jobs, while reserving managed endpoints for production inference.
This approach delivers the best of both worlds—data residency and customization on-prem, plus the scalability and managed services of the cloud.
Fine‑Tuning & Custom Modules
Domain Adaptation
Generic pre‑trained models often miss niche vocabulary. Fine‑tuning on domain‑specific corpora—medical journals, legal briefs, or proprietary logs—enables AI to grasp your industry’s unique terminology. For example, a biotech firm might fine‑tune a base LLM on genome studies, boosting accuracy in research summaries and experimental design support.
Modular Architecture
Encapsulate AI logic in microservices or separate modules. Expose clear APIs for inference, data preparation, and metrics collection. This separation allows you to swap engines (e.g., upgrading from GPT‑3.5 to GPT‑4) or switch frameworks (TensorFlow to PyTorch) without overhauling the entire application.
By investing in loosely coupled modules, you can pivot rapidly as AI libraries evolve. New training techniques or hardware accelerators (like NVidia TensorRT or AWS Inferentia) plug into your stack with minimal disruption.
Scalability & Deployment
Ensuring your AI solution can handle growing data volumes and unpredictable traffic patterns is essential. The right deployment strategy combines containerization, orchestration, monitoring, and cost controls to maintain performance and manage budgets.
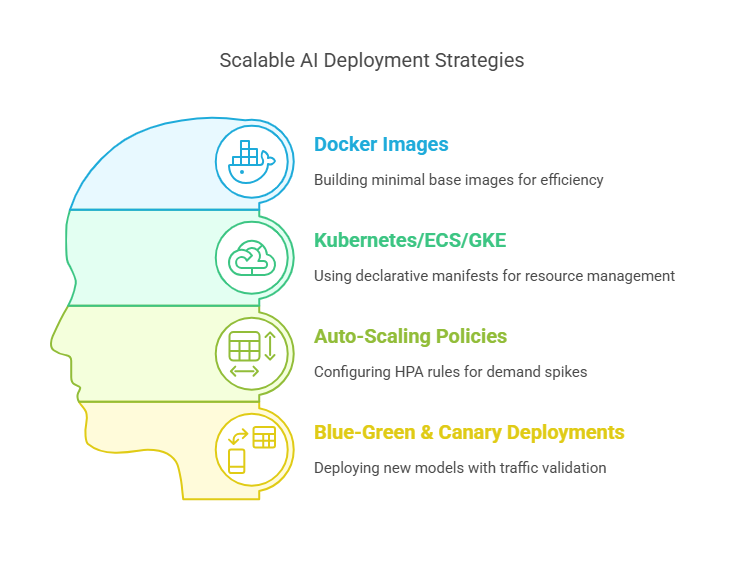
Containerization & Orchestration
Break your application into discrete, lightweight Docker containers for each microservice—web front-end, ETL ingestor, model inference, and analytics pipelines:
- Docker Images: Build minimal base images (e.g., Alpine Linux + Python) to reduce attack surface and improve startup times.
- Kubernetes/ECS/GKE: Use declarative manifests or CloudFormation templates to define Deployment, Service, and HorizontalPodAutoscaler resources.
- Auto-Scaling Policies: Configure HPA rules based on custom metrics (CPU, GPU utilization, queue length) so inference pods spin up when demand spikes.
- Blue-Green & Canary Deployments: Deploy new model versions alongside old ones, route a fraction of traffic for validation, and switch over seamlessly once metrics look good.
This modular architecture ensures zero-downtime updates and elastic scaling across cloud or on-prem clusters, keeping latency low even under heavy load.
Monitoring & Testing
Observability and robust testing guard against performance regressions and model drift:
- Prometheus & Grafana: Collect metrics—request latency, error rates, GPU memory usage—and visualize them in custom dashboards.
- Alerting Rules: Set Prometheus alerts for threshold breaches (e.g., 95th-percentile latency > 300ms) to trigger PagerDuty or Slack notifications.
- Automated Test Suites: Integrate unit tests for data transformations, integration tests for end-to-end flows, and performance tests that replay recorded traffic.
- Nightly Inference Validation: Schedule cron jobs that run your model against a benchmark dataset, compare output metrics to a baseline, and raise flags if accuracy drops.
By catching anomalies early and maintaining a feedback loop between operations and development, you keep service levels high and minimize user-impacting incidents.
Cost Optimization
AI workloads can be expensive—especially when GPU clusters run 24/7. Implement these techniques to control cloud spending without sacrificing performance:
- Spot/Preemptible Instances: Run non-critical batch jobs (retraining, data preprocessing) on discounted spot instances. Use checkpointing to resume from failures.
- Mixed Node Pools: Configure your cluster with CPU-only nodes for development and low-traffic inference, and GPU-enabled nodes for peak loads and complex model serving.
- Autoscaling Limits: Define upper and lower bounds on pods and node pools to prevent runaway costs during traffic spikes.
- Usage Analytics: Analyze historical resource utilization and schedule heavy workloads during off-peak hours when prices are lower.
With proactive cost monitoring tools and strategic use of cloud pricing tiers, teams often trim AI infrastructure spend by up to 30% while maintaining robust, responsive services.
Balancing Performance & Ethics
Delivering high-performance AI services while upholding ethical standards requires rigorous testing, transparent decision-making, and structured oversight. The following practices help you build resilient systems that stakeholders trust.
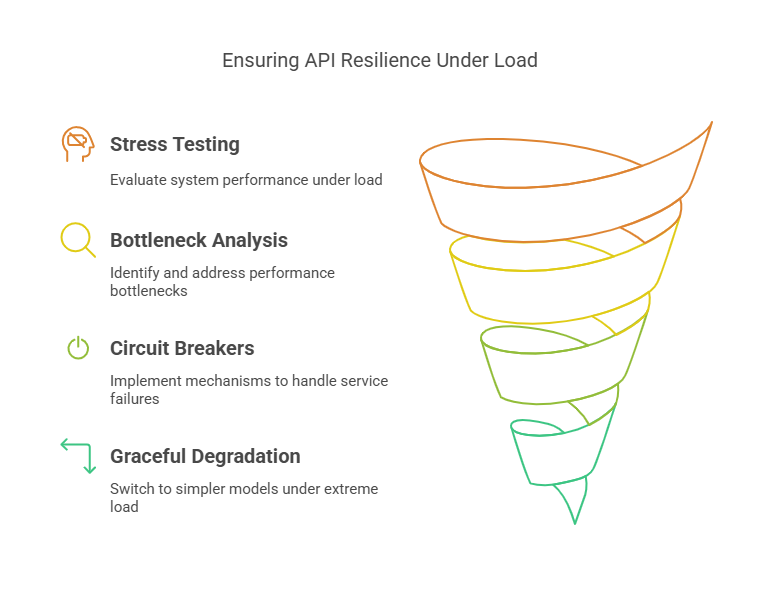
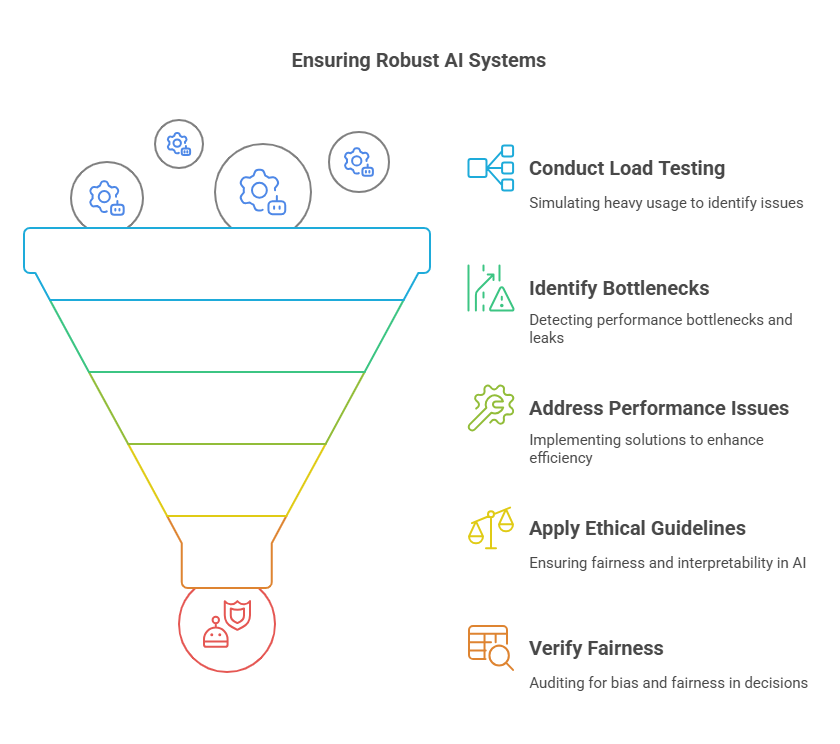
Load Testing & Resilience
Before exposing your AI endpoints to real users, simulate peak loads and failure scenarios:
- Stress Testing: Use tools like Locust or JMeter to generate thousands of simultaneous inference requests, measuring 95th-percentile latency, error rates, and resource usage.
- Bottleneck Analysis: Identify memory leaks, thread contention, or slow disk I/O in your profiling logs. Optimize hot paths in your code or increase replication where needed.
- Circuit Breakers: Implement patterns (via Hystrix or Istio) that detect unhealthy downstream services and automatically short-circuit calls—returning cached results or predefined fallbacks.
- Graceful Degradation: Under extreme load, switch to a lightweight “fast path” model or serve top-K cached answers to ensure your API remains responsive.
These measures prevent system-wide outages, allowing your AI service to maintain availability even when underlying infra or dependencies falter.
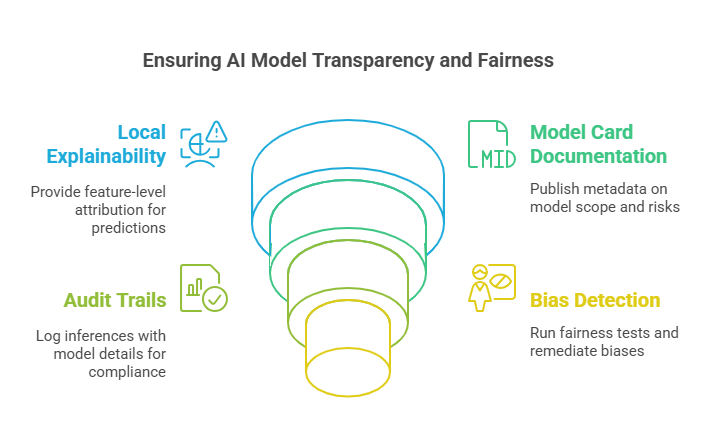
Ethical Frameworks & Interpretability
For applications impacting people’s lives—loans, hiring, medical advice—explainability and fairness are non-negotiable:
- Local Explainability: Integrate LIME or SHAP to generate feature-level attribution for each prediction, helping end-users and auditors see why a decision was made.
- Model Card Documentation: Publish metadata—training data sources, performance across demographic slices, and known limitations—to inform stakeholders of your model’s scope and risks.
- Audit Trails: Log every inference with model version, input features, and returned scores in a tamper-evident store, enabling full reconstruction of decisions for compliance reviews.
- Bias Detection: Periodically run fairness tests (statistical parity, equal opportunity) and remediate via re-sampling, re-weighting, or post-hoc calibration techniques.
By embedding interpretability and bias checks into your pipelines, you build trust with users, regulators, and executive sponsors alike.
Continuous Governance
AI is a fast-moving field, and your policies must evolve in step. A formal governance process ensures decisions remain aligned with organizational standards and external regulations:
- Governance Board: Establish a quarterly review panel comprising data science, security, legal, and business representatives to vet major upgrades—new frameworks, model families, or data sources.
- Policy Versioning: Maintain a living document of data-handling rules, security baselines, and ethical guidelines, with change logs and approval workflows tracked in source control.
- Risk Assessments: For each new model or feature, conduct privacy impact assessments (PIA) and ethical risk analyses to identify potential harm and mitigation steps before rollout.
- Training & Communication: Provide regular workshops and internal newsletters to update developers, analysts, and stakeholders on governance changes and best practices.
This structured, ongoing oversight prevents drift from established standards, keeps your team accountable, and ensures that your AI practice matures responsibly over time.
Conclusion
The right AI development framework underpins every dimension of your solution—cost, performance, security, and ethics. By matching frameworks to your team’s expertise, adopting a modular microservice architecture, and investing in robust CI/CD, monitoring, and governance processes, you build AI applications that stand the test of time. Whether you’re launching a pilot or scaling an enterprise‑wide AI platform, these principles ensure agility without sacrificing reliability.
Ready to build your AI stack?
Speak with our experts to design a customized, scalable, and secure AI development framework that aligns with your business goals!