Scaling AI from Pilot to Enterprise: A Roadmap for Seamless Deployment
Introduction
Picture this: your AI pilot didn’t just meet expectations—it exceeded them. The proof-of-concept delivered measurable ROI, and the early users can’t stop talking about the gains in speed, insight, and efficiency. Now the real challenge begins: scaling AI from pilot to enterprise- taking that single win and scaling it company-wide—across business units, geographies, and product lines—without choking your infrastructure or creating a thicket of one-off solutions.
That’s where disciplined engineering meets strategic foresight. Enterprise-grade deployment pipelines, containerized microservices, cloud orchestration, and Kubernetes-driven elastic scaling aren’t buzzwords; they’re the backbone of repeatable, resilient AI. The art lies in weaving these capabilities into a unified, automated framework—one that lets you stamp out new models and services with the same consistency you bring to your core products, while preserving the agility that made the pilot thrive.
Key Topics: Scaling AI from Pilot to Enterprise
- The Scaling Gap
Pilots behave in a sandbox; production is chaos. Once a model leaves the lab, you face security hardening, governance gates, cross-region failover, real-time monitoring, and cost controls—all competing for attention and budget. - The North Star
Aim for an AI backbone that auto-deploys containers, auto-scales on Kubernetes, and ships with CI/CD and end-to-end observability. It should handle a trickle of queries at 2 a.m. or a quarter-end surge—without a hiccup. - The Stakes
Move fast and AI becomes a flywheel of innovation. Drag your feet and that celebrated pilot turns into a “cool demo” that never made it to prime time.
Scaling AI from Pilot to Enterprise‑Scale Production
A proof-of-concept model coasts on a laptop or small cloud node. Scale it, and the cracks show fast: overnight retraining jobs throttle the cluster, integration points multiply, and teams on different stacks can’t even hit the endpoint. In short, yesterday’s lightweight demo now demands production-grade infrastructure.
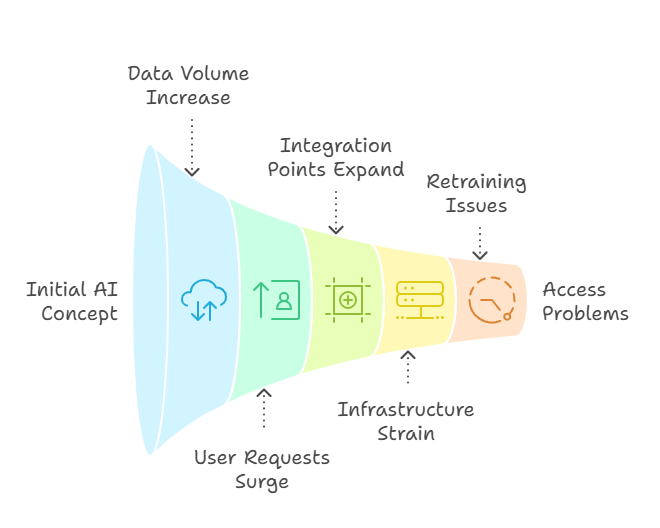
More boxes won’t save you. What scales is a codified pipeline: containerize the model with its exact dependencies, push it through automated CI/CD to Kubernetes, and wire fleet-wide telemetry to SLO dashboards. Lock in that loop and your one-off pilot becomes an enterprise-grade capability.
The Complexity of Enterprise Rollouts
Rolling out an AI pilot is one thing; rolling it out to an entire organization is another. You’ll face:
Fragmented Stacks
Marketing ships Python, Finance swears by Java, Support lives in R—one deployment script can’t bridge three languages.
Finite GPUs, Infinite Demand
Budgets cap the GPU fleet; 24/7 inference on aging hardware clogs pipelines and inflates latency.
Change Aversion
Teams wedded to familiar workflows fear downtime and new tooling, slowing the march toward a unified platform.
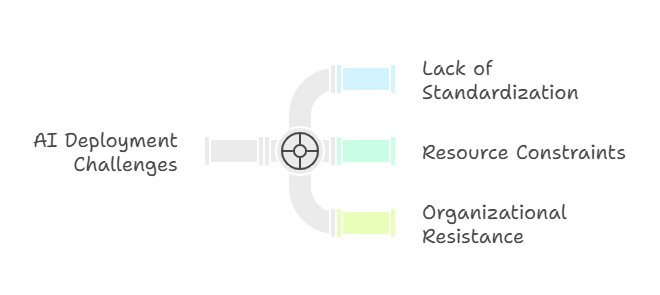
Fail to tackle these obstacles, and your AI pilot stays a one-hit wonder—leaving the projected ROI on the table.
Ready to accelerate your enterprise‑wide rollout?
Download our Scalable AI Deployment Toolkit and get checklists, templates, and best practices for every stage of the journey.
Tech Stack for Expanding AI From Prototype to Enterprise Scale
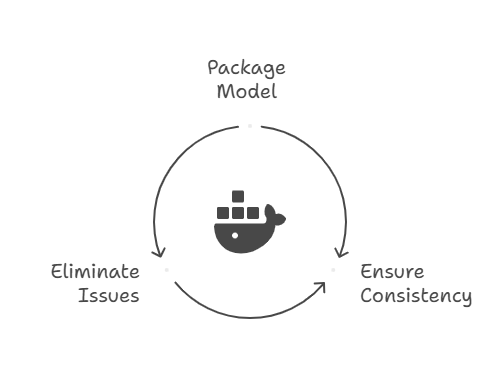
Containerization with Docker
Package the model, its libraries, and runtime in a Docker container and you get build-once, run-anywhere predictability—from on-prem racks to any cloud region. The result: zero “works on my machine” surprises.
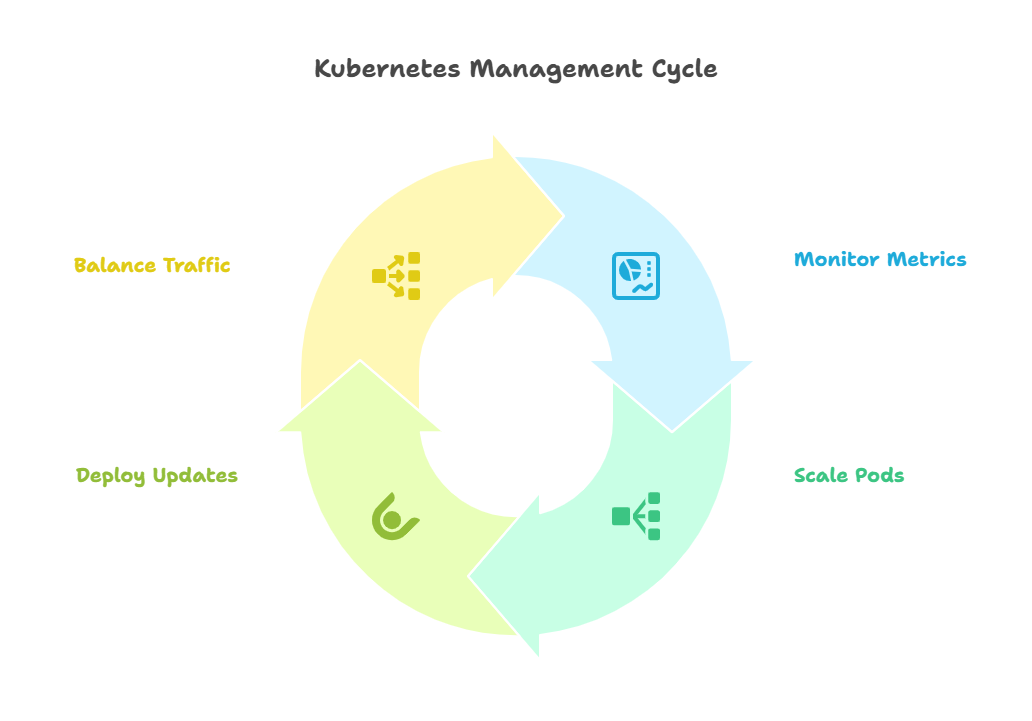
Orchestration via Kubernetes
With Kubernetes orchestrating the fleet, your AI services gain enterprise-grade muscle:
-
Elastic scaling on autopilot. Pods spin up or wind down the moment CPU, memory, or even a custom revenue-per-query KPI crosses a threshold—no ticket required.
-
Zero-downtime upgrades. Rolling deployments with live health probes let you cut over to a new model version while the old one keeps serving, so users never feel the switch.
-
Always-on performance. Built-in load balancing routes traffic across replicas to keep latency low, even during peak surges.
Elastic Cloud Infrastructure
AWS, Azure, and Google Cloud convert capacity into a utility: spin up managed Kubernetes nodes or on-demand VMs for a holiday rush, spin them down when the surge subsides, and pay only for the minutes you actually burn. That elasticity keeps performance high and budgets sane.

Standardized MLOps Pipelines
Think DevOps, but for models. A mature MLOps pipeline looks like this:
-
Version everything. Data, code, and model artifacts live in one source-of-truth repo, so every experiment is traceable and reproducible.
-
CI for intelligence. Automated tests and validation suites fire on every commit—catching data-drift, schema breaks, and performance regressions before they reach prod.
-
CD with a safety net. Proven models flow straight into production, complete with one-click rollback if real-time metrics dip below agreed SLOs.
Automate the pipeline and you eliminate manual slip-ups, enforce a single gold-standard workflow, and guarantee every team ships models with the same enterprise-grade rigor.
Need help mapping these strategies to your environment?
Schedule a Deployment Readiness Call for a tailored roadmap and technical assessment.
Success Story: Nationwide Retail Rollout
One district-wide pilot slashed overstock by 15%, proving AI-driven forecasting works. But extending that win to 300 stores risked swamping the chain’s infrastructure—and slowing down every point-of-sale in the process.
How they scaled, step by step
-
Containerize once, run everywhere. The team wrapped the forecasting engine and its Python stack into a single Docker image—guaranteeing bit-level consistency from test bench to store server.
-
Autoscale on demand. A managed Kubernetes service watched each location’s order traffic and spun pods up or down in real time, so quiet rural stores didn’t pay for the same horsepower as busy urban flagships.
-
Nightly MLOps cycle. Fresh point-of-sale data triggered an automated retraining job every evening, followed by validation checks before the new model went live at dawn.
-
Staged rollout, tight feedback loop. They launched in batches—10 stores, then 50, then the full fleet—tuning resource limits and alert thresholds after each wave.
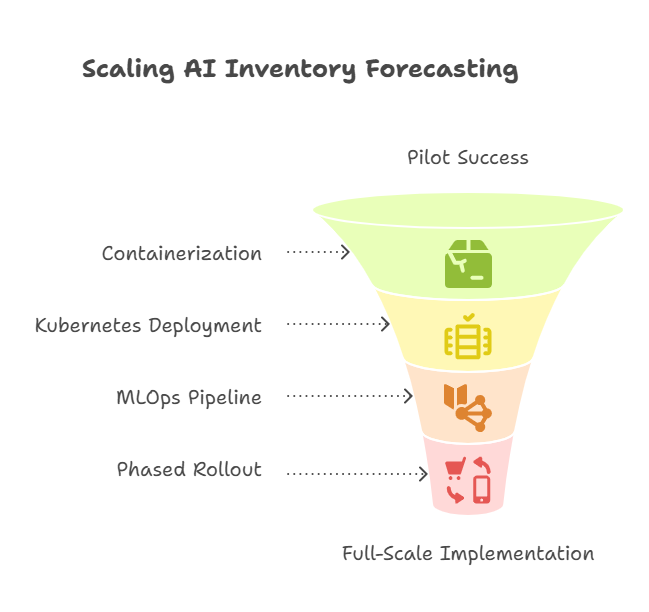
Outcome: Six months later, every store was live with the forecasting engine—waste down, revenue up. The standardized playbook turned expansion into a rinse-and-repeat exercise, letting new markets come online with virtually zero extra lift.
Conclusion
Scaling AI isn’t about tossing more GPUs at the rack—it’s about engineered discipline:
-
Package once, run anywhere. Containerize every model and dependency so consistency is built in, not hoped for.
-
Orchestrate automatically. Let Kubernetes handle elasticity, fail-over, and self-healing so your team focuses on innovation, not fire drills.
-
Industrial-grade MLOps. CI/CD pipelines for data and models bake governance and speed into the release process.
-
Roll out in waves. Start small, validate fast, and expand with confidence—turning every deployment into a predictable, low-risk play.
Lock these pillars together and your AI moves from lab curiosity to enterprise workhorse—delivering measurable gains across products, regions, and business lines.
Next Steps
Get Our Scalable AI Deployment Toolkit to access checklists and templates that simplify containerization, orchestration, and pipeline setup.
Schedule a Deployment Readiness Call for a 1:1 review of your current infrastructure and a customized scaling plan.
Share this post with your colleagues—help them overcome scaling challenges and drive enterprise‑wide AI success.